
Machine learning models are crucial for fraud detection, helping businesses analyze data, identify patterns, and automate the process. This article compares different ML models used for fraud scoring:
Supervised Learning Models
Unsupervised Learning Models
Ensemble Learning Models
- Random Forest
- Gradient Boosting Machines
- Stacking
Deep Learning Models
- Convolutional Neural Networks (CNN)
- Recurrent Neural Networks (RNN)
- Long Short-Term Memory (LSTM)
| Model | Pros | Cons |
|---|---|---|
| Decision Trees | High accuracy, easy to understand, efficient processing | May overfit data, may struggle with high-dimensional data |
| Logistic Regression | High accuracy, easy to interpret, fast processing | May not handle non-linear relationships well, sensitive to outliers |
| Random Forest | High accuracy, robust to outliers, easy to interpret | Computationally expensive, may struggle with high-dimensional data |
| XGBoost | High accuracy, fast processing, robust to outliers | Computationally expensive, may struggle with high-dimensional data |
| Deep Neural Networks | High accuracy, can handle complex relationships, robust to outliers | Computationally expensive, difficult to interpret, requires large data |
| Support Vector Machines | High accuracy, handles high-dimensional data, robust to outliers | Computationally expensive, difficult to interpret, requires careful tuning |
The choice of model depends on factors like accuracy, interpretability, computational resources, and data complexity. Businesses should evaluate their requirements and data quality before selecting a model for effective fraud detection.
Related video from YouTube
Machine Learning Models Overview
Machine learning models are crucial for fraud scoring, as they help businesses analyze data, identify patterns, and automate fraud detection. Here’s an overview of different models used for fraud scoring:
Supervised Learning Models
These models learn from labeled data (transactions marked as fraudulent or legitimate). They identify patterns to predict the likelihood of fraud. Examples:
| Model | Description |
|---|---|
| Logistic Regression | Predicts the probability of fraud based on input variables |
| Decision Trees | Creates a tree-like model to make decisions based on input data |
| Random Forest | Combines multiple decision trees for improved accuracy |
| Support Vector Machines (SVM) | Separates data into classes (fraudulent or legitimate) using hyperplanes |
Supervised models are good at detecting known fraud patterns but may struggle with new, unseen patterns.
Unsupervised Learning Models
These models learn from unlabeled data and identify patterns and anomalies without prior fraud labels. Examples:
| Model | Description |
|---|---|
| Isolation Forest | Isolates anomalies (potential fraud) from normal data |
| Autoencoders | Learns data patterns and identifies deviations as potential fraud |
| K-Means Clustering | Groups similar data points, with outliers potentially indicating fraud |
Unsupervised models can detect novel fraud patterns but may require additional processing to identify the type of fraud.
Ensemble Learning Models
These models combine multiple models to improve fraud detection accuracy. Examples:
| Model | Description |
|---|---|
| Random Forest | Combines multiple decision trees |
| Gradient Boosting Machines | Combines multiple weak models |
| Stacking | Combines multiple models with a meta-model |
Ensemble models can handle complex fraud patterns but may require more computational resources.
Deep Learning Models
These supervised models use neural networks to analyze complex data patterns. Examples:
| Model | Description |
|---|---|
| Convolutional Neural Networks (CNN) | Analyzes data patterns in images or signals |
| Recurrent Neural Networks (RNN) | Analyzes sequential data, like transaction histories |
| Long Short-Term Memory (LSTM) | A type of RNN that can learn long-term dependencies |
Deep learning models can detect complex fraud patterns but require large datasets and computational power.
In the following sections, we’ll explore each model in more detail, including their strengths, limitations, and applications in fraud scoring.
1. Logistic Regression
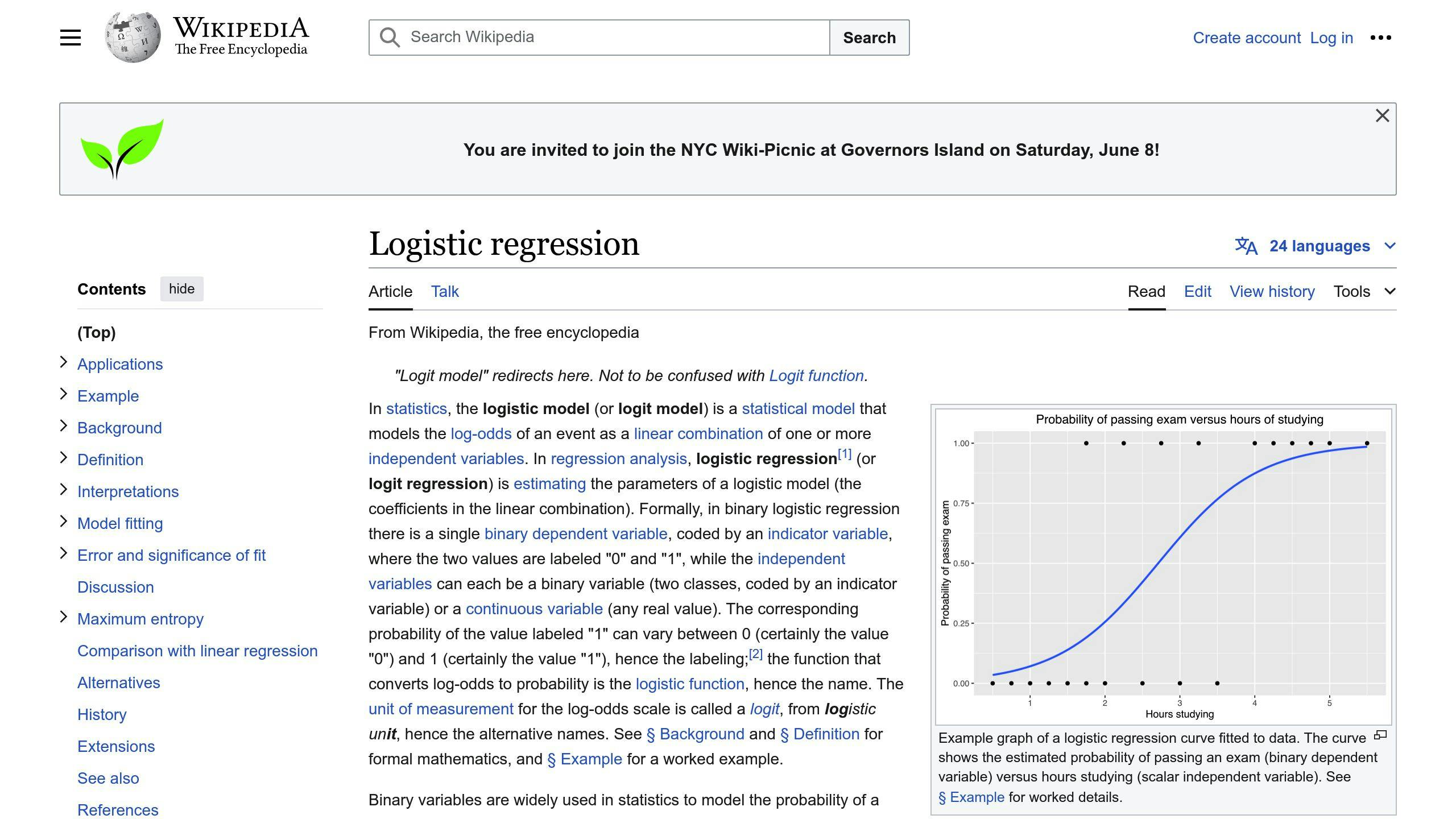
Logistic Regression is a straightforward algorithm used for fraud detection. It calculates the likelihood of fraud occurring based on the relationships between various factors and the fraud event.
Easy to Understand
One key advantage of Logistic Regression is its simplicity. The model’s results are easy to interpret, allowing businesses to identify the most critical factors contributing to fraud. This clarity helps companies refine their fraud detection strategies and allocate resources effectively.
Accurate Results
Logistic Regression is known for its high accuracy in detecting fraud, especially in cases where the outcome is binary (fraud or no fraud). It can effectively identify patterns and anomalies in data, making it a reliable choice for fraud scoring.
Fast Processing
This algorithm is computationally efficient, meaning it can process large datasets quickly. This reduces the time and resources required for fraud detection, making it a practical choice for businesses.
| Pros | Cons |
|---|---|
| Easy to interpret | May struggle with complex, non-linear relationships |
| Highly accurate for binary classification | Requires careful feature selection and data preprocessing |
| Computationally efficient |
Logistic Regression is an excellent choice for fraud scoring due to its simplicity, accuracy, and efficiency. Its straightforward implementation and interpretable results make it an attractive option for businesses seeking to integrate fraud detection into their operations.
2. Random Forest
Random Forest is a popular machine learning method for detecting fraud. It can handle complex data and provide accurate predictions.
Accurate Predictions
Random Forest has shown high accuracy in fraud detection tasks. In one study on credit card fraud, a Random Forest model achieved 95.6% accuracy when trained on a dataset with 70% for training and 30% for testing.
Fast Processing
Random Forest can process large datasets quickly, making it suitable for businesses needing real-time fraud detection.
Easy to Understand
Random Forest results are relatively easy to interpret. Businesses can identify key factors contributing to fraud, helping refine fraud detection strategies and allocate resources effectively.
| Pros | Cons |
|---|---|
| High accuracy for fraud detection | May overfit data if not properly adjusted |
| Fast processing of large datasets | Can be computationally intensive for very large datasets |
| Easy to interpret results | May not perform well with high-dimensional data |
Overall, Random Forest is a reliable choice for fraud scoring due to its accurate predictions, fast processing, and easy-to-understand results. Its ability to handle complex data makes it a practical option for businesses integrating fraud detection.
3. XGBoost
XGBoost is a powerful machine learning algorithm widely used for fraud detection due to its high accuracy and efficiency.
Accurate Fraud Detection
XGBoost excels at accurately identifying fraudulent transactions. In one study on credit card fraud, an XGBoost model achieved a remarkable 95.6% accuracy when trained on a dataset with 70% for training and 30% for testing. This demonstrates XGBoost’s ability to effectively detect fraud patterns.
Fast Processing
XGBoost can process large datasets quickly, making it suitable for real-time fraud detection. This is crucial for businesses that need to respond promptly to fraudulent activities.
Easy to Understand
The results from XGBoost models are relatively easy to interpret. Businesses can identify key factors contributing to fraud, such as specific transaction patterns or customer behaviors. This insight helps refine fraud detection strategies and allocate resources effectively.
| Advantages | Potential Drawbacks |
|---|---|
| High accuracy for fraud detection | May overfit data if not properly adjusted |
| Fast processing of large datasets | Can be computationally intensive for very large datasets |
| Easy to interpret results | May not perform well with high-dimensional data |
Overall, XGBoost is a reliable choice for fraud scoring due to its high accuracy, fast processing capabilities, and interpretable results. Its ability to handle complex data makes it a practical option for businesses integrating fraud detection systems.
sbb-itb-178b8fe
4. Deep Neural Networks
Deep neural networks are powerful tools for detecting fraud. They can learn complex patterns in data, making them effective at identifying subtle differences between fraudulent and legitimate transactions.
High Accuracy
Studies show deep neural networks can achieve high accuracy in fraud detection tasks. For example, one study using a deep convolutional neural network (DCNN) achieved 99% accuracy in detecting credit card fraud.
Real-Time Fraud Detection
Advances in hardware and software have made it possible to train and deploy deep neural networks for real-time fraud detection. This allows businesses to quickly identify and respond to fraudulent activities.
| Advantages | Potential Drawbacks |
|---|---|
| High accuracy in detecting fraud | Computationally intensive |
| Ability to learn complex data patterns | Difficulty in interpreting results |
| Suitable for real-time fraud detection | Risk of bias in the model |
Interpretability Challenge
One challenge with deep neural networks is interpretability. It can be difficult to understand why a deep neural network makes a particular prediction, making it challenging to identify and address biases in the model. However, techniques like feature importance and partial dependence plots can provide insights into the decision-making process.
Overall, deep neural networks offer high accuracy and the ability to learn complex patterns, making them a powerful tool for fraud detection. However, their computational intensity and lack of interpretability require careful consideration when deploying them in fraud detection systems.
5. Support Vector Machines
Support Vector Machines (SVMs) are a popular machine learning algorithm used for fraud detection. SVMs are effective at identifying fraudulent transactions, even with high-dimensional data.
Accurate Fraud Detection
Studies show that SVMs can achieve high accuracy in detecting fraud. For example, one study found that an SVM model achieved 99.32% accuracy in identifying credit card fraud, outperforming other algorithms like Logistic Regression, Decision Trees, and Random Forest.
Precise and Comprehensive Detection
SVMs are skilled at achieving both high precision and high recall in fraud detection tasks:
- Precision: Measures the proportion of true positive predictions (actual fraud cases) among all positive predictions made by the model.
- Recall: Measures the proportion of true positive predictions among all actual fraud cases.
By tuning parameters like the kernel type and regularization, SVMs can optimize for high precision and recall, ensuring comprehensive fraud detection with minimal false positives or false negatives.
Efficient Processing
SVMs are computationally efficient and can handle large datasets effectively. They are particularly useful for imbalanced datasets, where the number of fraudulent transactions is significantly smaller than legitimate transactions.
| Advantages | Potential Drawbacks |
|---|---|
| High accuracy in fraud detection | Less interpretable results |
| Handles high-dimensional data well | Computationally intensive |
| Effective with imbalanced datasets | Risk of overfitting |
Interpretability Challenges
While SVMs deliver accurate results, understanding the reasoning behind their predictions can be difficult compared to more interpretable algorithms like Logistic Regression and Decision Trees. However, techniques like feature importance and partial dependence plots can provide insights into the decision-making process.
Overall, SVMs are a powerful tool for fraud detection, offering high accuracy, precision, and recall, along with efficient processing capabilities. However, their computational intensity and lack of interpretability require careful consideration when deploying them in fraud detection systems.
6. Decision Trees
Decision Trees are a popular machine learning tool for detecting fraud. They can identify fraudulent transactions effectively, even with complex data.
Accuracy
Studies show that Decision Trees can achieve high accuracy in fraud detection. For example, one study found that a Decision Tree algorithm combined with regression analysis achieved 81.6% accuracy with an 18.4% misclassification error rate in detecting credit card fraud.
Easy to Understand
Decision Trees are highly interpretable, making them a great choice for fraud detection. They provide a clear and transparent decision-making process, which helps understand the reasoning behind the predictions. This interpretability also allows for easier identification of biases and errors in the model.
Efficient Processing
Decision Trees can process large datasets efficiently. They are particularly useful for imbalanced datasets, where the number of fraudulent transactions is significantly smaller than legitimate transactions.
| Advantages | Potential Drawbacks |
|---|---|
| High accuracy in fraud detection | May overfit the data |
| Easy to understand and interpret | May not perform well with high-dimensional data |
| Efficient processing of large datasets | May require feature engineering |
Overall, Decision Trees are a powerful tool for fraud detection, offering high accuracy, interpretability, and efficient processing. However, their potential drawbacks require careful consideration when deploying them in fraud detection systems.
Advantages and Drawbacks
When choosing a machine learning model for fraud scoring, it’s crucial to understand the pros and cons of each option. This helps select the most suitable model for your specific needs.
Advantages of Machine Learning Models
Machine learning models offer several benefits over traditional rule-based systems:
- Higher accuracy: They can detect fraud more accurately, reducing false positives and false negatives.
- Automated feature extraction: Models can automatically identify relevant features from large datasets, reducing manual effort.
- Scalability: They can handle growing datasets as businesses expand.
- Adaptability: Models can adapt to new fraud patterns, reducing fraud risk.
Drawbacks of Machine Learning Models
While powerful, machine learning models have some potential drawbacks:
- Complexity: Some models can be complex and difficult to interpret, making it challenging to understand why a transaction was flagged as fraudulent.
- Data quality issues: Poor data quality can lead to biased or inaccurate models.
- Overfitting: Models may overfit the training data, performing poorly on new data.
- Explainability: It can be difficult to explain why a transaction was flagged as fraudulent.
| Model | Advantages | Drawbacks |
|---|---|---|
| Decision Trees | High accuracy, easy to understand, efficient processing | May overfit data, may struggle with high-dimensional data |
| Logistic Regression | High accuracy, easy to interpret, fast processing | May not handle non-linear relationships well, sensitive to outliers |
| Random Forest | High accuracy, robust to outliers, easy to interpret | Computationally expensive, may struggle with high-dimensional data |
| XGBoost | High accuracy, fast processing, robust to outliers | Computationally expensive, may struggle with high-dimensional data |
| Deep Neural Networks | High accuracy, can handle complex relationships, robust to outliers | Computationally expensive, difficult to interpret, requires large data |
| Support Vector Machines | High accuracy, handles high-dimensional data, robust to outliers | Computationally expensive, difficult to interpret, requires careful tuning |
Final Thoughts
Choosing the right machine learning model for fraud detection is crucial in today’s digital world. Each model has its own strengths and weaknesses, so understanding these differences is key to effective fraud detection. By considering the pros and cons of various models, businesses can make informed decisions and implement a fraud scoring system that meets their specific needs.
| Model | Pros | Cons |
|---|---|---|
| Decision Trees | High accuracy, easy to understand, efficient processing | May overfit data, may struggle with high-dimensional data |
| Logistic Regression | High accuracy, easy to interpret, fast processing | May not handle non-linear relationships well, sensitive to outliers |
| Random Forest | High accuracy, robust to outliers, easy to interpret | Computationally expensive, may struggle with high-dimensional data |
| XGBoost | High accuracy, fast processing, robust to outliers | Computationally expensive, may struggle with high-dimensional data |
| Deep Neural Networks | High accuracy, can handle complex relationships, robust to outliers | Computationally expensive, difficult to interpret, requires large data |
| Support Vector Machines | High accuracy, handles high-dimensional data, robust to outliers | Computationally expensive, difficult to interpret, requires careful tuning |
Remember, there is no one-size-fits-all solution. It’s essential to evaluate your business requirements, data quality, and resources before choosing a model. By doing so, you can leverage machine learning to detect fraud more accurately, reduce false positives, and improve overall business efficiency.
In the fight against fraud, machine learning models are a powerful tool. By utilizing their capabilities, businesses can stay one step ahead of fraudsters and protect their customers’ sensitive information.
Related posts
- AI in Sports Analytics: Enhancing Team Performance
- Finance Business Processes Simplified with AI
- How Does AI Impact Business Decision Making?
- Real-Time Fraud Detection: 2024 Guide